
Carrera de Eliminación en Ciclismo de Pista: Patrones e Indicadores del Rendimiento
Daniel B Dwyer1, Bahadorreza Ofoghi2, Emy Huntsman3, Daniel Rossitto3, Clare McMahon3 y John Zeleznikow3
1Deakin University, Centre for Exercise & Sport Science, School of Exercise & Nutrition Sciences , Geelong , Australia
2Victoria University, School of Sport and Exercise, Melbourne, Australia
3Victoria University, School of Management and Information Systems, Melbourne, Australia
Artículo publicado en el journal PubliCE del año 2016.
Publicado 4 de julio de 2016
Resumen
Palabras clave: análisis de rendimiento, eventos múltiples, análisis estadístico, aprendizaje automático
INTRODUCCIÓN
El Omnium es una competencia de ciclismo de pista con múltiples eventos que fue introducida por primera vez por la Unión Ciclista Internacional (UCI) en 2007. Los ciclistas acumulan puntos Omnium en función del nivel de finalización de cada ciclista en una serie de eventos (los rangos más altos reciben puntos más bajos). Los ciclistas ganan el Omnium, completando todos los eventos con la menor puntuación total Omnium. Las exigencias de cada caso varían en una amplia gama de perfiles de aptitud física (desde esprint hasta resistencia) y en habilidades tácticas y técnicas (pruebas contrarreloj individuales frente a carreras con salida en masa). Así, para ganar el Omnium, el ciclista debe poseer una amplio rango de habilidades en ciclismo.
En 2009 el Omnium experimentó un cambio en diversos aspectos, la distancia de la mayoría de los eventos aumentó y la duración de la competencia aumentó de uno a dos días. Tal vez, el cambio más importante fue el incremento de cinco a seis en el número de eventos, con la incorporación de la Carrera de Eliminación (ER). La ER es un nuevo estilo de carrera que no había sido utilizado previamente en los campeonatos de la UCI. Después de que un grupo de hasta 24 ciclistas realizan una salida lanzada, cada dos vueltas durante un máximo de 50 vueltas, el último ciclista en cruzar la línea de llegada es eliminado de la carrera. El último ciclista que queda se considera ganador de la ER y los puntos Omnium se otorgan teniendo en cuenta el orden en que cada ciclista fue eliminado en la carrera.
La carrera ER es un reto para los ciclistas debido a su novedad. Son muy pocos los ciclistas o los entrenadores de ciclismo que poseen alguna experiencia de larga data en ER a nivel de competencia de élite y es diferente a los otros eventos Omnium. El caso más similar puede ser la Carrera por Puntos, en la que los ciclistas compiten para ganar esprints cada diez vueltas con el fin de acumular puntos. Sin embargo, la Carrera por Puntos es mucho más larga que la ER (120 y 80 vueltas para varones y mujeres respectivamente) y la exigencia de realizar esprints es mucho menos frecuente (cada 10 vueltas vs. cada 2 vueltas). Un importante desafío adicional de la ER es su demanda táctica sobre cada ciclista. Debido a que el objetivo principal de la ER es evitar quedar rezagado a lo último del pelotón, y no tratar de estar en el frente, que es lo típico en la mayoría de las carreras (por ejemplo, carrera por puntos), la dinámica del pelotón parece ser diferente a las demás carreras de largada en masa. Además, la carrera es una "muerte súbita", donde finalizar ultimo un esprint al principio de la carrera, hace que el ciclista quede eliminado y establece su rango para este evento, a diferencia de la Carrera por Puntos donde los primeros errores pueden ser compensados más adelante en la carrera.
Como evidencia adicional de las nuevas e inusuales demandas de la ER, un análisis del Omnium realizado previamente, reveló patrones típicos del rendimiento en cada uno de los eventos que so necesarios para ganar una medalla en el Omnium general (Ofoghi et al. 2012). Este análisis reveló correlaciones entre el rendimiento en varios de los eventos Omnium como la prueba de Persecución Individual (r=0,77) y la Prueba contrarreloj (r=0,79), con rango general en el Omnium. Los autores fueron capaces de demostrar con cierto grado de certeza, cual es el tipo de rendimiento que se requiere en cada uno de los eventos Omnium para crear una alta probabilidad de ganar una medalla en el Omnium. Sin embargo, en el mismo estudio, el rango en la ER presentó solo una baja correlación (r=0,59) con rango de general en el Omnium, lo que sugiere que la ER tiene un conjunto único de demandas que hacen que sea muy difícil para los ciclistas. De hecho, al ser una nueva carrera, podría ser que los ciclistas y sus entrenadores aun no hayan podido desarrollar una comprensión compartida de cuales serían las tácticas ideales para la carrera. Si este es el caso, entonces la dinámica de la carrera evolucionará durante los próximos años, lo que hace que sea sumamente interesante examinarla.
El éxito en la mayoría de las competencias deportivas está determinado por un conjunto complejo de factores relacionados con el rendimiento del atleta, su equipo, sus contrincantes y la interacción entre sus tácticas y las reglas del evento. Muchos atletas y entrenadores de nivel de élite conocen muchos de los factores determinantes básicos de éxito en sus deportes, pero pocos pueden afirmar que poseen un modelo que relacione precisamente y globalmente el rendimiento deportivo con la probabilidad de alcanzar el éxito. En una época en que muchos aspectos del rendimiento deportivo pueden ser, y están siendo medidos, las técnicas de manejo de datos pueden ser utilizadas para investigar grandes bases de datos de información sobre el rendimiento deportivo con el fin cumplir dos objetivos principales; la identificación de las características y/o patrones de rendimientos exitosos y el aporte de información para apoyar la toma de decisiones tácticas durante un evento, a través de análisis del rendimiento deportivo en tiempo real.
El objetivo del presente trabajo fue caracterizar el rendimiento de los mejores y peores ciclistas en la Carrera de Eliminación. En concreto, este trabajo describirá los cambios en la velocidad del pelotón durante la ER, identificará los patrones de movimiento de los mejores y peores ciclistas en el pelotón y utilizará técnicas de extracción de datos para identificar las características de rendimiento que se asocian con resultados exitosos.
MATERIALES Y MÉTODOS
Participantes
En este estudio se analizaron las Carreras de Eliminación de los Campeonatos Mundiales de ciclismo de pista de Melbourne (diciembre de 2010), Pekín (enero de 2011) y la Copa de Ciclismo de UCI (Unión Ciclista Internacional) en Manchester (febrero de 2011) y el Campeonato Mundial de la UCI en 2011, que se celebró en Apeldoorn, Países Bajos (marzo de 2011). En las cuatro carreras analizadas participaron 91 ciclistas, 66 de los cuales estaban solos, ya que algunos ciclistas corrían en varias Copas o Campeonatos Mundiales.
Procedimientos
Recolección y análisis de vídeos
El estudio fue aprobado por el Comité de Ética de Investigación Humana de la Universidad de Victoria. Las grabaciones de vídeo de las ER fueron analizadas con el software de análisis de vídeo Kinovea (v 0.8.15, http://www.kinovea.org). Todas las carreras fueron filmadas desde las gradas por encima de la recta de salida y la segunda curva, en frente a la línea de salida/llegada.
Utilizando la clasificación final de cada ciclista, realizamos un análisis retrospectivo del rendimiento. Para cada ciclo de eliminación de dos vueltas, analizamos el rendimiento de los ciclistas que finalizaron la ER en los lugares primero, segundo y tercero; y también a los ciclistas eliminados y a los que iban a ser eliminados en el siguiente ciclo de eliminación de dos vueltas. Por lo tanto, podríamos describir el rendimiento de cada ciclista eliminado en las cuatro vueltas previas a su eliminación. Se recogieron datos de vídeo en cada vuelta y cuando el ciclista que se ubicaba último en el pelotón cruzaba la línea de llegada. Las variables recogidas para el análisis incluyeron el tiempo en la vuelta, posición horizontal y vertical en el pelotón, ubicación en el pelotón y la distancia detrás de la cabeza del pelotón. La Tabla 1 proporciona una lista de variables y definiciones.
Tabla 1. Atributos de rendimiento y mediciones de velocidad en las vueltas identificados en el análisis de las Carreras de Eliminación. Los tiempos de vuelta y velocidades de vuelta fueron registrados utilizando la función cronómetro del software de análisis de vídeo Kinovea. Se obtuvieron los tiempos de vuelta (ss.00) para cada ciclista en cuestión y los mismos fueron registrados en el momento en que la rueda trasera de ese ciclista cruzaba la línea de inicio/llegada en cada vuelta. Ver la Figura 1 para obtener una descripción de las mediciones de posición.
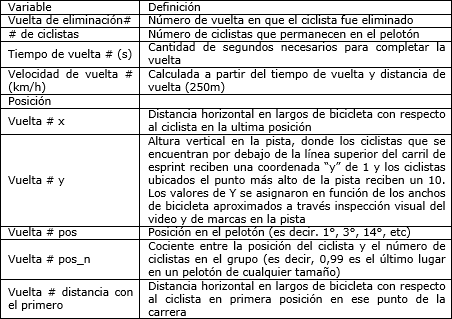
Si un ciclista quedaba fuera del marco del vídeo, sus puntos de dato/s no se consideraban en el conjunto de datos. Si era posible estimar con exactitud la posición del ciclista (por ejemplo, si estaba parcialmente en marco o se acababa de mover), la inclusión de los datos quedaba bajo la decisión del investigador. Dos de los autores realizaron todos los análisis de vídeo, trabajaron desde el principio juntos para desarrollar la metodología y el procedimiento de codificación. Realizaron un chequeo cruzado de sus codificaciónes para garantizar la coherencia y luego procedieron a analizar todos los datos de vídeo utilizando un método consistente.
Identificación de las etapas dentro de la ER
Teniendo en cuenta la disminución progresiva del tamaño del pelotón a lo largo de la ER, observamos cambios en las demandas del pelotón (i.e. cambios en la velocidad de la vuelta) y en la dinámica dentro del mismo durante la carrera. Nuestra valoración subjetiva era que podrían existir dos o tres etapas dentro de la ER, cada una con una combinación propia particular de demandas. Por lo tanto, analizamos esta posibilidad mediante la evaluación de los cambios en la única variable de medición que se puede comparar razonablemente durante toda la duración de la carrera; la velocidad del pelotón vuelta a vuelta. Para determinar la posible existencia y la localización aproximada de las etapas dentro la ER, se utilizó un método de aprendizaje automático no supervisado. El aprendizaje automático es la subsección de aprendizaje en la cual un sistema de inteligencia artificial intenta aprender automáticamente. En el aprendizaje no supervisado, el sistema recibe sólo la entrada (estimulo), y no hay información sobre la salida (resultado) esperada. El sistema aprende para poder reproducir el patrón al cual ha sido expuesto. El método de agrupamiento que utilizamos fue el conocido algoritmo k-means (MacQueen 1967). El objetivo de las técnicas de agrupamiento consiste en agrupar los datos en grupos de items similares. Se utilizó el paquete de aprendizaje automático WEKA (MacQueen 1967) para ejecutar el algoritmo k-means y el método codo (elbow) para estimar el mejor número de agrupamientos (clusters) en el conjunto de datos de la ER (Mardia et al. 1979). Cuando al añadir otro grupo no se logró un mejor modelado de los datos se identificó el número óptimo de agrupamientos. Para ello, se calculó la suma de errores cuadrados dentro del agrupamiento (WCSSE) del análisis de conglomerados con el número de agrupamientos. Para una mayor confiabilidad de los resultados, utilizamos dos funciones kernel para el cálculo de los valores de WCSSE utilizando el método k-means; principalmente las funciones de distancia Euclídea y distancia de Manhattan. Los datos ER utilizados para este análisis fueron promedio, desviación estándar, velocidad mínima y máxima de los ciclistas en cada uno de los cuatro ciclos de análisis de vueltas.
Modelado y predicción de rendimiento
El modelado y la predicción de rendimiento se realizó en tres etapas: i) el desarrollo de un sistema de clasificación considerando todos los atributos relacionados a ER, ii) selección de aquellos atributos que tienen una mayor relación con el rendimiento que pueden ser utilizados para el modelado y la predicción del rendimiento en carreras de eliminación, y ii) modelar una sistema de clasificación para la predicción de los rendimientos de los ciclistas basado en el conjunto óptimo de atributos.
Análisis de todos los atributos de rendimiento
Para encontrar una manera sistemática para predecir el rendimiento de los ciclistas, en términos de si ganarían o no una medalla en el Omnium (es decir, terminar la ER en un cierto rango), se utilizó una técnica de aprendizaje automático supervisado. La clasificación es un método que predice la pertenencia a grupos a partir de instancias de datos (casos individuales) dentro de un conjunto de datos. Un estudio anterior sobre ER en el contexto del ciclismo de pista Omnium demostró que los ganadores de medallas Omnium (varones) finalizaron la ER en el 6to lugar en promedio (Ofoghi et al. 2012). Tomamos este rango en la ER como límite para la definición de ciclistas exitosos y no exitosos en la ER que compiten en un Omnium.
Se utilizó el conjunto de datos de las ER que comprendía todos los atributos de rendimiento descritos anteriormente (Tabla 1), excluyendo los atributos que no serían de utilidad obvia; número de corredores en el pelotón y número de vuelta en la que se eliminó un ciclista. Realizamos un procesamiento previo del conjunto de datos convirtiendo los rangos en ER a sólo dos categorías: i) rango ER = 1 para todo rango ER ≤6 y rango ER = 2 para todo rango ER> 6. Estas dos categorías de rango ER representaban a los ciclistas exitosos y ciclistas no exitosos de este análisis de predicción del rendimiento. Utilizamos el método de clasificación Naïve Bayes (George y Langley 1995) en WEKA para modelar una metodología de clasificación automática capaz de asignar un nivel de clase (es decir, exitoso o no exitoso) a un registro de datos de rendimiento que contemplaba los atributos de rendimiento mencionados previamente.
Identificación de los atributos que permiten una mayor predicción del rendimiento
Dado el gran número de atributos relacionados con el rendimiento que se utilizan para el modelado y la predicción que describimos en la sección anterior, utilizamos una serie de métodos de selección basados en el aprendizaje automático para encontrar los atributos más relevantes. Las técnicas que utilizamos fueron la selección de un subconjunto de características basadas en la correlación (correlation-based feature subset selection)(Hall, 1998), evaluación del índice de potencia (gain ratio evaluation) (Hall y Smith, 1998) evaluación de la información sobre la base de la potencia (information gain-base evaluation) (Forman, 2003), evaluación de la simétría basada en la incertidumbre (symmetrical uncertainty–based evaluation) (Hall y Smith 1999; Press et al. 1988) y la selección de un subconjunto de características basada en Wrapper (wrapper-based feature subset selection) (Kohavi y John 1997).
Sólo consideramos los cinco atributos más predictivos seleccionados/identificados por cada técnica. Luego se identificaron los cinco mejores atributos de predicción utilizando una técnica de turno rotativo (round robin). En primer lugar, creamos el conjunto de unión de todos los atributos ubicados en primer lugar en las cinco primeras listas arrojadas por los diferentes métodos de selección de características. Luego obtuvimos un conjunto de unión de este conjunto y los atributos ubicados en el segundo lugar en los resultados de las cinco listas. Continuamos este procedimiento hasta que el conjunto de unión estuviera compuesto por 5 atributos de rendimiento distintos. Para entender la importancia relativa del conjunto de atributos seleccionado, finalmente clasificamos los 5 mejores atributos seleccionados utilizando una técnica de selección de atributos con capacidad de clasificación (es decir, la técnica de información basada en la potencia o information gain-based technique, Foreman 2003).
Modelización y predicción del rendimiento
Para establecer un modelo de comportamiento de los ciclistas no exitosos y exitosos, y comprender cuan precisamente el modelo podría predecir el rendimiento de los ciclistas, realizamos una vez más un experimento de clasificación basado en el aprendizaje automático. Utilizamos el mismo clasificador Naïve Bayes utilizado anteriormente y consideramos únicamente los cinco atributos más predictivos del rendimiento y de clasificación en no exitosos/exitosos.
RESULTADOS
Identificación de las etapas dentro de la ER
El análisis de agrupamiento de las mediciones de velocidad por vuelta reveló que no se observó ninguna nueva mejora significativa en la precisión (WCSSE) mediante el modelado de la ER con más de 2 agrupamientos (etapas).
Por lo tanto, a partir de la perspectiva de las demandas fisiológicas determinadas por la velocidad del pelotón, podemos considerar que la ER tiene dos etapas, cada una con una combinación diferente de promedio y varianza en la velocidad del pelotón. La Tabla 2 resume los resultados de este análisis que indica que el punto medio de la transición entre las etapas se produce 20 vueltas antes del final de la ER.
Tabla 2. Características de cada etapa de la prueba de eliminación. Los valores de la velocidad por vuelta fueron analizados utilizando el agrupamiento no supervisado k-means para determinar si había alguna evidencia de etapas. Utilizando el método de codo se identificaron dos etapas. *La velocidad en la Etapa 2 fue significativamente diferente a la de la Etapa 1.

Cambios en la velocidad del pelotón durante toda la Carrera de Eliminación
La Figura 1 presenta los cambios relativamente consistentes en la velocidad del pelotón en las cuatro ER que analizamos. En general la velocidad promedio se mantuvo relativamente alta (52,2 km/h) al principio de la carrera y disminuyó progresivamente (49,9 kilómetros/h) hacia el final de la carrera (antes de ~ 20 vueltas para terminar). Durante esta primera etapa de la carrera, el rango de velocidades dentro de cada ciclo de eliminación de dos vueltas, fue relativamente pequeño (2,9 km/h). En la etapa posterior de la ER (después de ~ 20 vueltas para terminar), la velocidad del pelotón siguió disminuyendo ligeramente, pero se produjo un aumento pronunciado en el rango de velocidades (9,5 km/h).
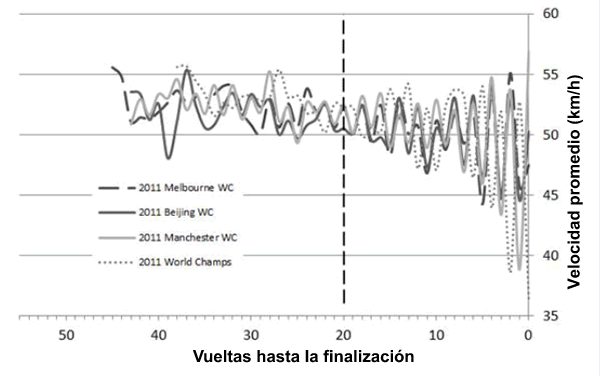
Figura 1. Cambios en la velocidad media de pelotón durante toda la carrera eliminación. La línea vertical discontinua representa la frontera entre la primera etapa (izquierda) y la segunda etapa (derecha) de la carrera y cada una de las etapas se caracterizó por diferentes patrones en la velocidad del pelotón. La variación (rango y SD) en la velocidad media de pelotón presentó una tendencia a ser mayor en las últimas 20 vueltas de la carrera ER.
Modelado y predicción del rendimiento
En la carrera de eliminación se analizaron veinticuatro atributos de rendimiento mediante el método de clasificación Naïve Bayes supervisado. El modelo resultante fue capaz de clasificar los ciclistas como exitosos (haber finalizado en sexto lugar o mejor) y no exitosos (finalizaron después del sexto lugar) con una precisión de 95,83%, lo que implica que el método era muy confiable para ser utilizado con fines de modelado de rendimiento, entrenamiento o para fines de predicción.
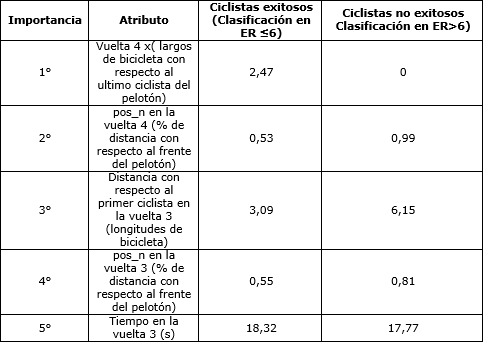
Los cinco mejores atributos de rendimiento fueron seleccionados utilizando cinco métodos de selección diferentes de características y los resultados fueron similares, pero no iguales. Por tanto, como conjunto final de los cinco mejores atributos de rendimiento se seleccionaron los atributos de rendimiento con el mayor ranking agregado en los cinco métodos; Distancia con respecto al primer lugar en la vuelta 3, pos_n en la vuelta 3, tiempo en vuelta 3 (s), vuelta 4 x, pos_n en la vuelta 4.
Atributos de rendimiento de los ciclistas exitosos y no exitosos
La Tabla 3 resume los resultados de nuestro análisis de los datos obtenidos en las ER y revela cuales fueron los atributos más predictivos para los ciclistas exitosos y no exitosos en las ER. En el punto de la eliminación (es decir, señalado como vuelta 4 de un ciclo de 4 vueltas), los ciclistas exitosos tienden a estar 2,47 largos de bicicleta mas adelante de la parte posterior del pelotón, o si lo expresamos en relación al número cambiante de ciclistas en el pelotón, se encuentran en el medio (53%). En la vuelta antes de que un ciclista sea eliminado, los ciclistas exitosos tienden a estar a 3 (3,09) longitudes de bicicleta con respecto a la parte frontal del pelotón, mientras que los ciclistas no exitosos permanece dos veces más atrás (6,15). Cuando la distancia hasta el frente del pelotón se normaliza en función de la variación en el tamaño del pelotón, los ciclistas exitosos tienden a permanecer en los rangos intermedios (55%) y los ciclistas sin éxito se encuentran al final del pelotón (81%). El quinto rasgo de rendimiento más predictivo es el tiempo de vuelta en la vuelta previa a la eliminación (Tiempo en la vuelta 3 (s)). Los resultados revelaron un tiempo de vuelta corto para los ciclistas no exitosos y por lo tanto una velocidad promedio más rápida en esta vuelta, en comparación con los ciclistas exitosos.
Tabla 3. Últimos cinco atributos de rendimiento más predictivos de los ciclistas exitosos y no exitosos en la carrera de eliminación.
También se analizó la información sobre la posición y el cambio de posición de los ciclistas durante todo el ciclo de eliminación mediante estadísticos descriptivos simples. La Figura 2 representa las posiciones de los ciclistas en el primer lugar en las vueltas eliminación. Los ganadores de la carrera ER siempre se mantuvieron por delante de la última fila de ciclistas (es decir, mas de una longitud de bicicleta por delante del último ciclista), por lo general entre las filas 1-4, y 1-3 anchos de bicicleta por encima de la línea interior del velódromo (es decir, nunca en el carril central del velódromo).
En contraste con los ciclistas ganadores, los ciclistas que se encontraban a una vuelta de la eliminación, frecuentemente se ubicaban en la última fila de ciclistas (es decir, 0 longitudes bicicleta con respecto al último ciclista) y sólo 1-2 anchos de bicicleta con respecto a la línea interior del velódromo (Figura 3).
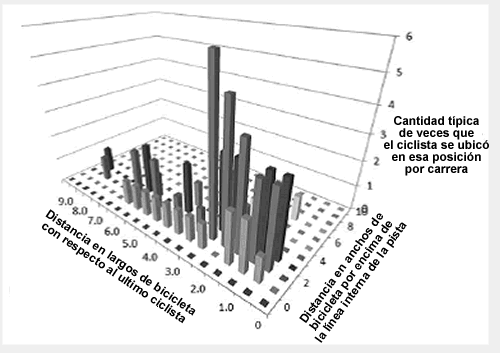
Figura 2. Posiciones típicas de los primeros ciclistas en una vuelta de eliminación. Las barras más altas de esta tabla representan las posiciones en el pelotón ocupadas con mayor frecuencia por los ciclistas que se ubicaron en la primera posición (es decir, en el medio del pelotón).
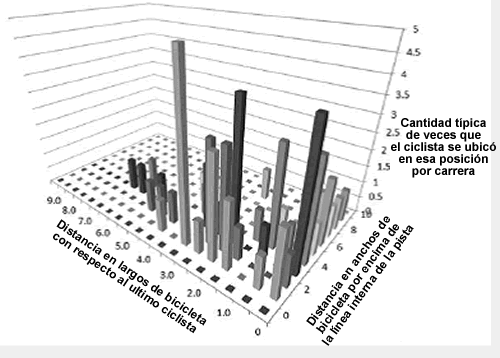
Figura 3. Posiciones típicas de los ciclistas eliminados una vuelta antes de la eliminación. Estos ciclistas con frecuencia se ubicaron en la línea interna (un ancho de la bicicleta por encima de la línea interna de la pista) y en la última fila del pelotón, incluso una vuelta antes de la eliminación.
Aunque la posición horizontal (x) en la que se elimina un ciclista se encuentra necesariamente en la última fila de ciclistas del pelotón, es instructivo conocer en que lugar de la última fila tendían a encontrarse. Los ciclistas que se eliminaban con mayor frecuencia eran los más cercanos a la línea interior del velódromo y la frecuencia disminuía mientras "más alto" se ubicaban en el velódromo (aumento en el número de anchos de bicicleta por encima de la línea interior del velódromo).
DISCUSIÓN
Este es el primer estudio que presenta un análisis del rendimiento en la Carrera de Eliminación que forma parte del ciclismo de pista Omnium. Se utilizó una variedad de metodologías de aprendizaje automático para analizar una gran base de datos sobre características de rendimiento. Nuestros resultados aportan información sobre el patrón de cambios en la velocidad promedio del pelotón durante la ER, sobre los atributos de rendimiento que mejor pueden predecir el éxito y también información estratégica que puede ser utilizada por ciclistas y entrenadores.
Al considerar las demandas de velocidad de la ER, nuestro análisis reveló que la ER tiene dos etapas que se juntan, en promedio, 20 vueltas antes del final de la carrera. La primera etapa se caracteriza por tener una velocidad media relativamente alta y una baja variación en la velocidad. Estas características probablemente se deben a la gran cantidad de ciclistas del pelotón que pueden mantener una velocidad alta y una baja percepción del riesgo de eliminación, lo que permite algunos ataques o cambios en la velocidad. Parecería que la velocidad promedio disminuye progresivamente en esta etapa, lo que indicaría una combinación entre la disminución en el número de ciclistas del pelotón y los efectos de la fatiga. En la segunda etapa de la ER se observa una tendencia hacia una mayor variación en la velocidad que la observada en la primera etapa. En la segunda etapa hay menos de 10 ciclistas en el pelotón que han completado las 30 vueltas y ahora se enfrentan al riesgo inmediato de eliminación. Así, mientras que el pelotón mantiene disminuciones en la velocidad promedio relativamente alta, se observa un aumento en la variación de la velocidad, a medida que los ciclistas individuales lanzan ataques estratégicos con el fin de evitar la eliminación y eliminar a otros ciclistas.
Cuatro de los cinco atributos de rendimiento más predictivos de los ciclistas en la ER, se relacionan con su posición y su cambio de posición en el pelotón. Teniendo en cuenta que seguimos la posición de la mayoría de los ciclistas durante cuatro vueltas sucesivas, logramos confirmar que la posición en la vuelta previa a la eliminación (vuelta 3) y en la vuelta de eliminación (vuelta 4) son los factores más importantes. También nos pareció que era igualmente importante identificar los atributos de los ciclistas exitosos y de los no exitosos, con el fin de ofrecer consejos sobre qué hacer y qué no hacer.
El predictor de éxito más potente en la ER fue la posición horizontal (x) de los ciclistas en cualquier vuelta de eliminación. No es sorprendente que los ciclistas no exitosos hayan sido típicamente los últimos del pelotón (es decir, en la última fila de ciclistas). La estadística más reveladora fue que los ciclistas exitosos no eran los que estaban solo una longitud de bicicleta por delante de los últimos, ni tampoco los que estaban en la parte delantera del pelotón. Por lo general, los ciclistas exitosos se encontraban con mayor frecuencia en el medio del pelotón (un promedio de 2,47 largos de bicicleta con respecto al último ciclista) y por lo general evitaban estar en la última fila del pelotón en cualquier vuelta. Este resultado también indica que la táctica de tratar de encabezar el pelotón, que puede parecer ser el lugar más seguro, no es la típica elección de los ciclistas exitosos. Incluso en las vueltas en las que no hay eliminación, los ciclistas exitosos permanecen más cerca de la parte delantera del pelotón (3,09 largos de bicicleta) que los ciclistas no exitosos (6,15 largos) pero no se ubican realmente en el frente del pelotón. Quienes están en el medio del pelotón tienen la ventaja de no tener que trabajar tan duro como los que se encuentran en la parte delantera o los que hacen grandes cambios en su posición dentro de cada ciclo de eliminación de dos vueltas (por ejemplo, desde la parte trasera hacia la parte delantera del pelotón). Los ciclistas exitosos también tienden a pedalear en los tres carriles interiores del velódromo (es decir, anchos de bicicleta por encima del carril interno del velódromo). Esto les permite recorrer una distancia de vuelta más corta y por lo tanto con una menor velocidad de vuelta que los ciclistas que pedalean en los carriles "superiores".
Los ciclistas no exitosos, eliminados en séptimo lugar o por encima de este, tendieron a permanecer en el último 20% del pelotón en la primera vuelta antes de ser eliminados. También tendían a pedalear en un carril más alto que los ciclistas exitosos (4,07 vs 3,25 anchos de bicicleta desde el carril interior del velódromo). En la vuelta que los ciclistas no exitosos fueron eliminados, se ubicaban en la última fila en el pelotón; pero lo que nuestro análisis (Figura 3) también reveló fue que muchos ciclistas, exitosos y no exitosos, se eliminan más cerca del interior de la pista de la fuera de la misma. Esto confirma las observaciones subjetivas de los autores de que un error que frecuentemente cometen los ciclistas es quedarse "atrapado" en la parte trasera del pelotón por el carril interno del velódromo. En esta posición particular, casi no hay oportunidades para cambiar de posición y evitar la eliminación.
El menos potente de los cinco mejores atributos de rendimiento fue el tiempo de vuelta (tiempo en la vuelta 3) en la vuelta previa a la vuelta de eliminación, que es también la vuelta que se produce inmediatamente después de una vuelta de eliminación. Los ciclistas no exitosos presentaron un tiempo de vuelta promedio inferior al de los ciclistas exitosos, lo que sugiere que en esta vuelta pedalean con una velocidad más alta. Esto podría deberse a que llevan una velocidad mayor a la de los ciclistas exitosos sobre la línea de eliminación hacia la siguiente vuelta.
Alternativamente, podría deberse a que tienen que pedalear más rápido para mejorar su posición desde la parte trasera del grupo hacia la parte delantera, en un intento por evitar la eliminación en la siguiente vuelta.
Las técnicas de aprendizaje automático han sido utilizadas para analizar el ciclismo en pista Omnium (Ofoghi et al., 2010) y otros deportes (Ofoghi et al. 2011). El presente trabajo pone de manifiesto la utilidad de estas metodologías para obtener información que puede ser aplicada por atletas de élite y entrenadores para describir las exigencias del evento. Sin embargo, aceptamos que el presente trabajo posee limitaciones relacionadas con las complejas interacciones entre la capacidad fisiológica del ciclista, sus tácticas y las posteriores demandas de la carrera, y que nuestras conclusiones no pueden ser aplicadas a ciclistas de sexo femenino. Sin embargo, las técnicas de aprendizaje automático pueden revelar las características de rendimiento de los atletas más exitosos, tanto en términos de sus aptitudes físicas como de sus estrategias de carrera. Finalmente, el aprendizaje automático también podría ser utilizado para crear un modelo matemático de rendimiento deportivo que podría ser utilizado durante un evento para ayudar con las decisiones estratégicas.
Aplicaciones prácticas
El presente trabajo proporciona información práctica para entrenadores y ciclistas que compiten en la Carrera de Eliminación. Las demandas de velocidad de la ER varían entre las dos etapas de la carrera. Desde el principio hasta ~ 20 vueltas para el final, la velocidad promedio del pelotón es relativamente alta, y sólo se observan pequeñas variaciones en la velocidad, sin embargo, en las últimas 20 vueltas, la variación en la velocidad promedio vuelta a vuelta es mayor y por lo tanto más exigente para los ciclistas. Los atributos de rendimiento más importantes de los ciclistas ER se relacionan con su posición en el pelotón. Los ciclistas exitosos tienden a permanecer en el medio del pelotón y no más de 3 anchos de bicicleta con respecto al carril interno del velódromo. Los ciclistas no exitosos normalmente permanecen en el último 20% del pelotón y en los carriles superiores del velódromo.
Agradecimientos
Nos gustaría dar las gracias al Instituto Australiano del Deporte por su ayuda en la obtención del video de la Carrera de Eliminación que analizamos, específicamente a Alec Buttfield. Para realizar este trabajo no recibimos ningún tipo de financiamiento.
Referencias
1. Forman G. (2003). An extensive empirical study of feature selection metrics for text classification. Journal of Machine Learning Research: 1298-1305
2. George H.J., Langley P. (1995). Estimating continuous distributions in Bayesian classifiers. Proceedings of the Eleventh Conference on Uncertainty in Artificial Intelligence. Morgan Kaufmann Publishers Inc., Montreal, Canada, pp. 338-345
3. Hall M.A. (1998). Correlation-based Feature Subset Selection for Machine Learning. PhD Dissertation, University of Waikato, Deprtment of Computer Science. Hamilton, NZ. p. 178
4. Hall M.A., Smith L.A. (1998). Practical feature subset selection for machine learning. Computer Science ’98 Proceedings of the 21st Australasian Computer Science Conference ACSC’98. Springer, Perth, pp. 181-191
5. Hall M.A., Smith L.A. (1999). Feature Selection for machine learning: Comparing a correlation-based filter approach to the wrapper. Twelfth International Florida Artificial Intelligence Research Society Conference, Florida, pp. 235 – 239
6. Kohavi R., John G.,H. (1997). Wrappers for feature subset selection. Artif. Intell. 97: 273-324
7. MacQueen J.B. (1967). Some Methods for classification and Analysis of Multivariate Observations. Proceedings of 5th Berkeley Symposium on Mathematical Statistics and Probability. University of California Press, California, pp. 281–297
8. Mardia K.V., Kent J.T., Bibby J.M. (1979). Multivariate analysis. Academic Press, London
9. Ofoghi B., Zeleznikow J., MacMahon C. (2011). Probabilistic modelling to give advice about rowing split measures to support strategy and pacing in race planning. Int. J. Perf. Anal. Spor. 11: 239-253
10. Ofoghi B., Zeleznikow J., MacMahon C., Dwyer D. (2010). A Machine Learning Approach to Predicting Winning Patterns in Track Cycling Omnium. Ifip. Adv. Inf. Comm. Te. 331: 67-76
11. Ofoghi B., Zeleznikow J., MacMahon C., Dwyer D.B. (2012). Modeling and Analyzing Track Cycling Omnium Performances Using Statistical and Machine Learning Techniques. Journal of Sport Sciences: 31(9), 954-962.
12. Press W.H., Flannery B.P., Teukolski S.A., Vetterling W.T. (1988). Numerical recipes in C: the art of scientific computing. Cambridge University Press, Cambridge